What is HDFS?
HDFS is a file system designed for storing very large files with streaming data access patterns, running clusters on commodity hardware.
What are the key features of HDFS?
HDFS is highly fault-tolerant, with high throughput, suitable for applications with large data sets, streaming access to file system data and can be built out of commodity hardware.
What is a block and block scanner in HDFS?
Block – The minimum amount of data that can be read or written is generally referred to as a “block” in HDFS. The default size of a block in HDFS is 64MB.
Block Scanner – Block Scanner tracks the list of blocks present on a DataNode and verifies them to find any kind of checksum errors. Block Scanners use a throttling mechanism to reserve disk bandwidth on the datanode.
What is the difference between NameNode, Backup Node and Checkpoint NameNode?
NameNode: NameNode is at the heart of the HDFS file system which manages the metadata i.e. the data of the files is not stored on the NameNode but rather it has the directory tree of all the files present in the HDFS file system on a hadoop cluster. NameNode uses two files for the namespace-
fsimage file– It keeps track of the latest checkpoint of the namespace.
edits file-It is a log of changes that have been made to the namespace since checkpoint.
BackupNode:
Backup Node also provides check pointing functionality like that of the checkpoint node but it also maintains its up-to-date in-memory copy of the file system namespace that is in sync with the active NameNode.
Checkpoint Node:
Checkpoint Node keeps track of the latest checkpoint in a directory that has same structure as that of NameNode’s directory. Checkpoint node creates checkpoints for the namespace at regular intervals by downloading the edits and fsimage file from the NameNode and merging it locally. The new image is then again updated back to the active NameNode.
Is NameNode also a commodity?
No. Namenode can never be a commodity hardware because the entire HDFS rely on it. It is the single point of failure in HDFS. Namenode has to be a high-availability machine.
What is commodity hardware?
Commodity Hardware refers to inexpensive systems that do not have high availability or high quality. Commodity Hardware consists of RAM because there are specific services that need to be executed on RAM. Hadoop can be run on any commodity hardware and does not require any super computers or high-end hardware configuration to execute jobs.
What is a metadata?
Metadata is the information about the data stored in datanodes such as location of the file, size of the file and so on.
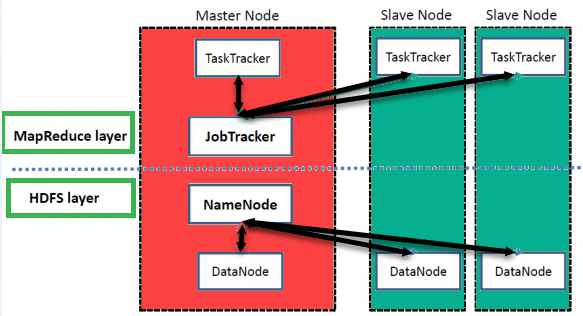
What is a Datanode?
Datanodes are the slaves which are deployed on each machine and provide the actual storage. These are responsible for serving read and write requests for the clients.
What is a daemon?
Daemon is a process or service that runs in background. In general, we use this word in UNIX environment. The equivalent of Daemon in Windows is “services” and in Dos is” TSR”.
What is a job tracker?
Job tracker is a daemon that runs on a Namenode for submitting and tracking MapReduce jobs in Hadoop. It assigns the tasks to the different task tracker. In a Hadoop cluster, there will be only one job tracker but many task trackers. It is the single point of failure for Hadoop and MapReduce Service. If the job tracker goes down all the running jobs are halted. It receives heartbeat from task tracker based on which Job tracker decides whether the assigned task is completed or not.
What is a task tracker?
Task tracker is also a daemon that runs on datanodes. Task Trackers manage the execution of individual tasks on slave node. When a client submits a job, the job tracker will initialize the job and divide the work and assign them to different task trackers to perform MapReduce tasks. While performing this action, the task tracker will be simultaneously communicating with job tracker by sending heartbeat. If the job tracker does not receive heartbeat from task tracker within specified time, then it will assume that task tracker has crashed and assign that task to another task tracker in the cluster.
What is a heartbeat in HDFS?
A heartbeat is a signal indicating that it is alive. A datanode sends heartbeat to Namenode and task tracker will send its heart beat to job tracker. If the Namenode or job tracker does not receive heart beat then they will decide that there is some problem in datanode or task tracker is unable to perform the assigned task.
What is a ‘block’ in HDFS?
A ‘block’ is the minimum amount of data that can be read or written. In HDFS, the default block size is 64 MB as contrast to the block size of 8192 bytes in Unix/Linux. Files in HDFS are broken down into block-sized chunks, which are stored as independent units. HDFS blocks are large as compared to disk blocks, particularly to minimize the cost of seeks. If a particular file is 50 mb, will the HDFS block still consume 64 mb as the default size? No, not at all! 64 mb is just a unit where the data will be stored. In this particular situation, only 50 mb will be consumed by an HDFS block and 14 mb will be free to store something else. It is the MasterNode that does data allocation in an efficient manner.
How indexing is done in HDFS?
Hadoop has its own way of indexing. Depending upon the block size, once the data is stored, HDFS will keep on storing the last part of the data which will say where the next part of the data will be. In fact, this is the base of HDFS.
How can you overwrite the replication factors in HDFS?
The replication factor in HDFS can be modified or overwritten in 2 ways-
- Using the Hadoop FS Shell, replication factor can be changed per file basis using the below command-
$hadoop fs –setrep –w 2 /my/test_file (test_file is the filename whose replication factor will be set to 2)
- Using the Hadoop FS Shell, replication factor of all files under a given directory can be modified using the below command-
$hadoop fs –setrep –w 5 /my/test_dir (test_dir is the name of the directory and all the files in this directory will have a replication factor set to 5)
Explain the difference between NAS and HDFS?
- NAS runs on a single machine and thus there is no probability of data redundancy whereas HDFS runs on a cluster of different machines thus there is data redundancy because of the replication protocol.
- NAS stores data on a dedicated hardware whereas in HDFS all the data blocks are distributed across local drives of the machines.
- In NAS data is stored independent of the computation and hence Hadoop MapReduce cannot be used for processing whereas HDFS works with Hadoop MapReduce as the computations in HDFS are moved to data.
What is the process to change the files at arbitrary locations in HDFS?
HDFS does not support modifications at arbitrary offsets in the file or multiple writers but files are written by a single writer in append only format i.e. writes to a file in HDFS are always made at the end of the file.
Who is a ‘user’ in HDFS?
A user is like you or me, who has some query or who needs some kind of data.
Is client the end user in HDFS?
No, Client is an application which runs on your machine, which is used to interact with the Namenode (job tracker) or datanode (task tracker).
What is ‘Key value pair’ in HDFS?
Key value pair is the intermediate data generated by maps and sent to reduces for generating the final output.
What is the difference between MapReduce engine and HDFS cluster?
HDFS cluster is the name given to the whole configuration of master and slaves where data is stored. Map Reduce Engine is the programming module which is used to retrieve and analyze data.